Designing for Failure: Networking
Designing for Failure
Virtualization Series
Overview
Virtualization offers many benefits which I will not cover here as most of you are already well aware of many of them as they apply to your environments. The consolidation of servers and hardware can help reduce costs and improve resource utilization. In a physical world this usually means co-locating applications on the same servers but in a virtual environment it is more common to see one application installed per server. This provides isolation between applications making configuration, troubleshooting, and upgrades simpler as there aren’t other locally installed business applications to worry about. In either scenario however consolidation does bring a few risks, and somewhat more so in a virtual environment, one of which is that many servers now share a common set of software and hardware and can all be impacted in the case of a problem with any of the underlying and supporting components. This risk can be mitigated by designing the virtual environment in such a manner as to be able to survive the various failure scenarios that can be foreseen. In other words, by designing for failure.
First let's take a look at the basic structure of a virtual environment.
- Host hardware
- Network switches
- Routers
- Storage
- Racks
- Datacenter
We can further break this down into smaller components:
Host hardware
- CPU
- RAM
- Network interfaces
- Firmware and drivers
- Storage adapters
- Firmware and drivers
- Power supplies
Network switches
- Host connections
- Uplinks
- Power supplies
Storage switches (when using a dedicated storage network)
- Host connections
- Storage array controller connections
- Power supplies
Storage system
- Storage array controllers
- Power supplies the controllers
- Power supplies for the disk enclosures
Rack Infrastructure
- Power delivery to the racks (PDUs)
Datacenter Infrastructure
- Power to the datacenter
- Cooling
As you can see there are many components and when designing for failure you can take the endeavor as far as you want to go. I will attempt to cover a few redundancy scenarios in the sections below.
Designing Network Redundancy
There are various areas related to networking where we want to have redundancy. On the network infrastructure side, namely the part of the network typically administered by a networking team, we want redundancy for switching and routing. So at a minimum we need to have two switches, each connected to two routers, ideally with multiple connections. This would amount to four pieces of networking equipment. If you choose to use layer 3 switches, that is switches that have routing capabilities, you can reduce this to two.
This might look like:
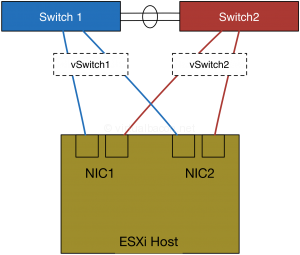
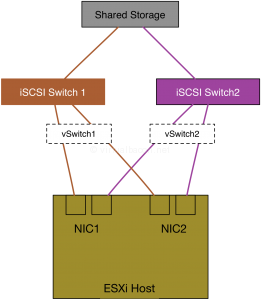
If the storage networking is separate, such as with fiber channel or many iSCSI storage networks, you will want to have a similar setup there with the difference usually being that only storage switches are involved, and they usually do not connect to each other in order to maintain completely isolated fabrics.
For example:
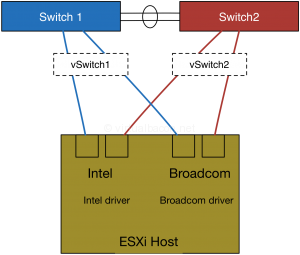
At the virtualization host hardware level we want to provide redundancy for the network connectivity as well. If we have network interfaces built into the motherboard, as many servers do, then we also want to have a separate network adapter in the host as well. In order to provide networking redundancy at the firmware and driver level we also want to ensure that the networks adapters are of a different make and model and that they use different chipsets. For example one network adapter might be an Intel brand while another one might be Broadcom. Whether they are the same speed is up to you, though I would recommend it for additional redundancy and predictability in performance, which affects availability.
Why would we go to the extent of choosing different brands and chipsets? Well because firmware can have issues, and drivers can fail, either at the time of install or as they are updated over time as part of normal life cycle and maintenance operations. By ensuring that drivers and firmware are different on separate networks adapters, and by using separate adapter ports as uplinks to virtual switches, you can ensure that network connectivity is maintained in case of a failure at those levels. Is it likely? I have experienced this at least three times over the years and where I had the host and virtual networking configured as such connectivity was maintained throughout the firmware or driver issue.
I mentioned using different make and model adapter ports as uplinks to virtual switches to provide redundancy to the vSwitch uplinks. This might look like the following:
Putting all the pieces together here is what a redundant networking design for a virtual infrastructure might look like.
Hardware:
Server
Intel dual port 10 Gb network adapter (x2)
Broadcom dual port 10 Gb network adapter (x2)
Dual SD cards (for esxi boot)
Server switches (x2)
Storage switches (x2)
Layer 3 core switches (x2)
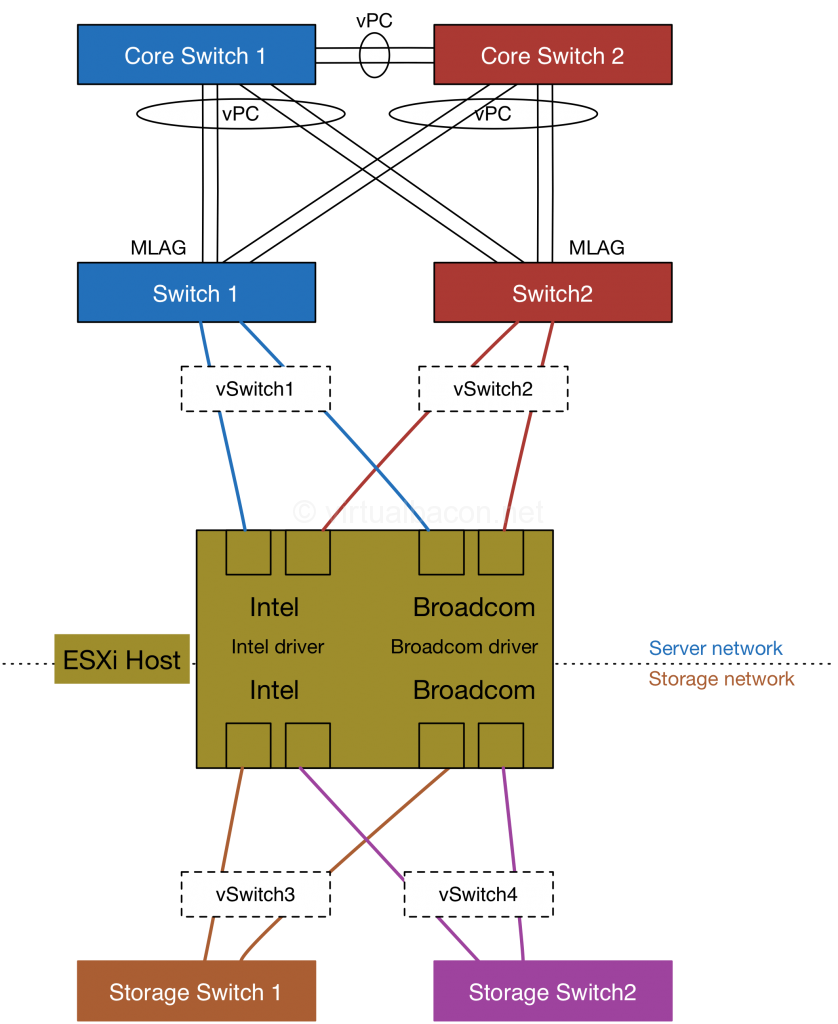
The virtual switches have the following settings configured for redundancy:
- Beacon probing enabled to detect upstream switch or link failures.
- Multiple vSwitch uplinks using one port from each adapter.
- Multiple uplinks from different physical switches for added redundancy.
Other notes
The core switches are connected via vPC so that they present to the downstream switches as a single switch. Each switch closest to the server is uplinked to two separate core switches using multiple cables such that two connections go to one core switch while the other two connections go to the other other switch. This ensures connectivity is retained to the downstream switches and to the esx hosts in the event of a core switch failure (or one or more links).
You can take designing for failure pretty far depending on how you define the acceptable level of risk and what the failure domain should be. I hope that you find the information above useful in helping you decide what level of redundancy you want to provide for your environment. As you can see not all increases in fault tolerance necessarily require spending more money than you would otherwise. A little time spent thinking about this end to end can have a large impact in the resilience and availability of your networking.
Enjoy this article?
Recent Posts
- Deploying the PernixData Management Server Virtual Appliance
- New Book “Designing A Storage Performance Platform” by Frank Denneman Available for Download!
- vExpert 2016 Application period is open!
- PernixData at VMworld US 2015
- PernixData at Virtualization Field Day 5
- Avoid problems when removing datastores from ESXi
- PernixData FVP 2.0 Overview
- Designing for Failure: Networking
- Reading S.M.A.R.T. disk data in ESXi
- Real World IIS/.Net Workload Acceleration with PernixData
- Blade Servers: Boot options for leveraging server-side flash
- Real World Domain Controller on FVP
- Swing by the Las Vegas VMUG Holiday Party on Dec. 6!
- Holiday vBeers tonight at 5:30 at the Bellevue TapHouse
- Speeding Up Real World Sharepoint Workloads with PernixData FVP
- Accelerating Real World SQL Workloads with PernixData FVP
- Portland VMUG on Nov 12, 2013
- Why you should join your local VMware User Group (VMUG) – and participate!
- A New Chapter – PernixData
- A Look at the Brocade 6510 Fibre Channel Switch
Categories
- Certification (5)
- Community (7)
- Event (1)
- Firewall Administration (1)
- Hardware (5)
- Network Administration (8)
- Performance (12)
- Storage (9)
- VDI (1)
- Virtualization (37)
- Windows Administration (2)
Tags
#vDB Blogroll
- BrainFloss
- Damian Karlson
- Gabriel Chapman
- Jason Langer
- MWPreston Dot Net
- Valco Labs
- VMCutlip
- vSential
- vTesseract
- WhiteBoard Ninja
Blogroll
- A glimpse into the life of IT
- blog.scottlowe.org
- Cloudjock.com
- Eric Sloof
- Frank Denneman's Blog
- Seattle VMUG LinkedIn Group
- Seattle VMUG Page
- Seattle VMUG Twitter Feed
- VMware Blogs



